OSSYM2025: The economics of running an independent search engine
This is a presentation I gave to the 7th International Open Search Symposium in Helsinki on 10 Oct 2025. It was part of their Industry Track on Alternative Search Engines.
One of the projects within the Open Search Foundation is Open Web Search which builds the Open Web Index, although they don’t have an end-user facing internet search interface. One of the objectives of this presentation was to indicate that it is viable for an organisation to build a genuinely useful independent internet search which is sustainable from a cost perspective.

Hi, my name is Michael Lewis, and I’m here to talk about the economics of running an independent search engine.
It is based on my experience building and maintaining searchmysite.net over the past 5 years.
This is a search engine for personal websites.
- One of its aims is to help find real content by real people from their personal websites, which can be hard to do now on the big search engines, and one of the innovations it introduced to help do this is to heavily downrank content which contains adverts.
- Another of its aims is to show that an internet search engine can be self-sustaining in terms of costs without advertising.
It is this last point I’m going to cover today, in 3 parts;
- general notes about costs,
- revenue models, and
- income vs expenses in practice.
Although it is relatively small, the lessons are real, and I believe would apply to a larger scale operation.
The first topic is general notes about costs
-
One of the key costs is building the index
- You can buy data from providers such as Bing, but this is obviously very expensive, and of course means you are not independent.
- I looked at using Common Crawl (this project predated the Open Web Index), but this was several terabytes which would have been very expensive in terms of storage and data transfer fees, and I probably wouldn’t have used much of it anyway (for example, one source suggests OpenAI filtered out about 90% of Common Crawl for GPT-3, with deduplication, blacklists and so on).
- So I decided to build my own index, and looked at tools such as Apache StormCrawler and Nutch. But, based on the idea that search is better with more good data and worse with more bad data, I soon reached the conclusion that…
-
You don’t want to index everything, because
- Most of the internet is rubbish now (Google appears to index trillions of pages but only saves around “hundreds of billions” in their search index, suggesting even they throw most of it out).
- So the question then is how to, firstly, find content, and secondly, identify whether it is good or not.
- That topic really deserves a whole presentation in itself, but for now I’ll just say searchmysite.net finds content via user submissions and determines whether to index it or not with a moderation layer. This works okay, although the issue is that it leads to slow growth (there have been roughly 1000 new sites every 1.5 years), and wouldn’t scale rapidly.
-
over time searchmysite.net has also narrowed its focus to just “personal websites” (to do one thing and to try to do it well). It is also self-hostable so it was originally hoped people would set up their own instances each indexing different parts of the internet (such as forums, news sites, wikipedia) and that these could be combined with a federated search interface to provide a wider internet search.
-
On the search side, the big issue is bots. This is a problem for internet sites in general, but for search engines there is the additional problem of Search Engine Optimisation practitioners running “scraping footprints” which generate a huge amount of search traffic from proxy farms of residential IPs which are pretty much impossible to block. On the best days, only around 1% of searches are from real users, while on bad days it can be less than 0.0001%. This means it is essential that serving search results not be computationally expensive, which was a factor in my stopping the local LLM 2 years back, unless you want to spend a lot of money to help spammers.
-
The final general point is around open source
- Clearly using open source solutions such as Apache Solr is great because they are tried and tested at can scale.
- searchmysite.net is fully open source itself, which is good for full transparency of indexing and so on, although isn’t a magic bullet to get lots of contributions.

The next topic is revenue models
-
As per the Open Search Foundation objectives, it would be great if search could be run as government funded public service, but until that point I think we need alternatives.
-
A common pattern for many search startups is to get a lot of investment without any idea as to how to make money, so they often spend a lot of money quickly and when they run out of money they either fail or resort to advertising.
-
One problem with advertising was highlighted by the founders of Google in their famous paper from 1998, where they pointed out the conflict of interest between a search engine company wanting to make money from advertising and the users wanting good results.
- The problem with advertising is much deeper than that though - advertising creates a financial incentive for people to produce lots of low quality content filled with adverts (“blog spam” and nowadays “AI slop”) and not only that but it creates a financial incentive to manipulate search results to drive more traffic to this lower grade content - they only spend money renting proxy farms to run their scraping footprints because of the potential advertising revenue.
-
Alternative search funding models include:
- Subscription based model, i.e. you pay some kind of fee to perform searches. That can work quite well, but the issue I had is that you need to invest heavily up-front to get a product good enough to pay for from the outset, making it difficult to bootstrap and grow organically.
- Another approach is donations. Although that essentially makes it a charity, which may or may not be sustainable long term.
- The model searchmysite.net uses, and I believe is the first to use, is to fund itself with a paid search-as-a-service.
- When you prove you own your domain and pay a fee, you get access to a console where you control your indexing and enable a nice API.
- Looking through some of the support forums for the big search engines there’s a familiar pattern of small businesses asking why the traffic to their businesses has has dramatically fallen, and there’s no-one to answer their questions. So I’m convinced that, for a big search engine, tens of millions of site owners would pay a small fee for official support and likely tens of thousands would pay a higher fee for enterprise-level support, which would likely be enough to cover the costs of running a large scale search engine.
-
You may have noticed that I talk about covering running costs. I’m not sure it would be possible to run a hugely profitable search engine without advertising, but I don’t think it is an issue as long as you cover costs, because you could view your search engine as a “loss leader” to draw customers to your other services.
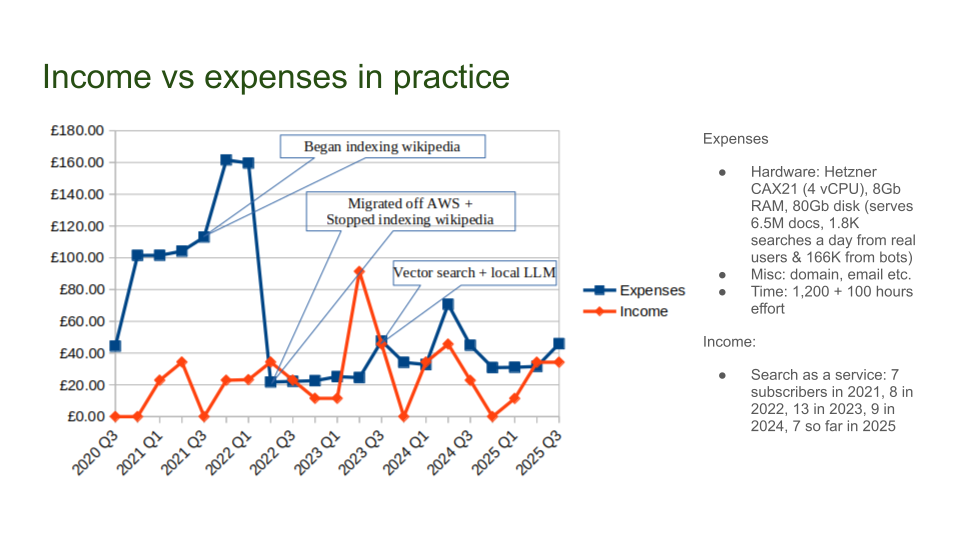
Now to cover the income and expenses in practice. Here’s the graph of income and expenses over the past 5 years.
-
On the expenses graph, there are three key points
- indexing wikipedia added a lot of costs due to the additional storage requirements,
- migrating off AWS significantly reduced the costs (it was about 5 times more expensive, and crucially had lots of unpredictable extras), and
- increasing the server spec a couple of years ago to enable vector search and a local LLM increased costs a little.
-
I’ve since switched these off, so the current servers are higher spec than I need.
-
But I’ve had no issues with a peak load of 1.8 thousand searches a day from real users and 166 thousand searches a day from bots, and was fine indexing 6.5 millions documents from wikipedia, and I know from experience that Solr can scale to billions of documents and millions of daily searches.
-
The biggest expense though is time and effort, not just to build the system but to support and maintain it. I’ve probably spent over 1,200 hours over the past 5.5 years, and open source contributors around 100 hours, which at the average IT hourly rate would make it very expensive:-)
-
As for income, you can see that some quarters this has been more than enough to cover costs, and (at least since migrating off AWS) has roughly been breaking even.
Again, I know these are all relatively small numbers, but I do think the lessons would still apply in a much larger scale operation.
I think the conclusion from all of this is that I believe it is possible to build a genuinely useful independent internet search, that is (crucially) sustainable from a cost perspective, if you:
-
Use heuristics for more targeted indexing. Don’t try to index the whole internet.
-
Manage costs carefully. Don’t use expensive providers, and don’t forget about time & effort:-)
-
Use alternative revenue models like search as a service. Don’t start out with no idea how to fund it, and don’t resort to advertising.
If you have any questions, I’ve put my contact details here and you are welcome to reach out to me afterwards, and I think there should be some time available now for questions too.